Recursive Language Models (RLMs) have gotten a bunch of hype recently. After seeing some discussion on them, I was curious to reproduce the results. It proved somewhat difficult.
The work ultimately looks like a negative result disguised as a positive one (outside of a bespoke, unpublished benchmark). Additionally, the blog post introducing them is very blatantly false. A negative finding here is interesting, but it’s best to call a spade a spade.
To begin, why write this? I found out two of my friends independently wasted time on RLMs — and eventually came to my same conclusion. They seem to want to avoid the sort of public fight a post like this generates, especially given the research group behind the work seems very effective at using social media. Also, the blog post also appears to be straight-up false, which annoyed me since that’s all many people will read.
RLMs: Blog, Paper, Code
My code dump: https://github.com/CoffeeFlux/rlm-repro-attempt
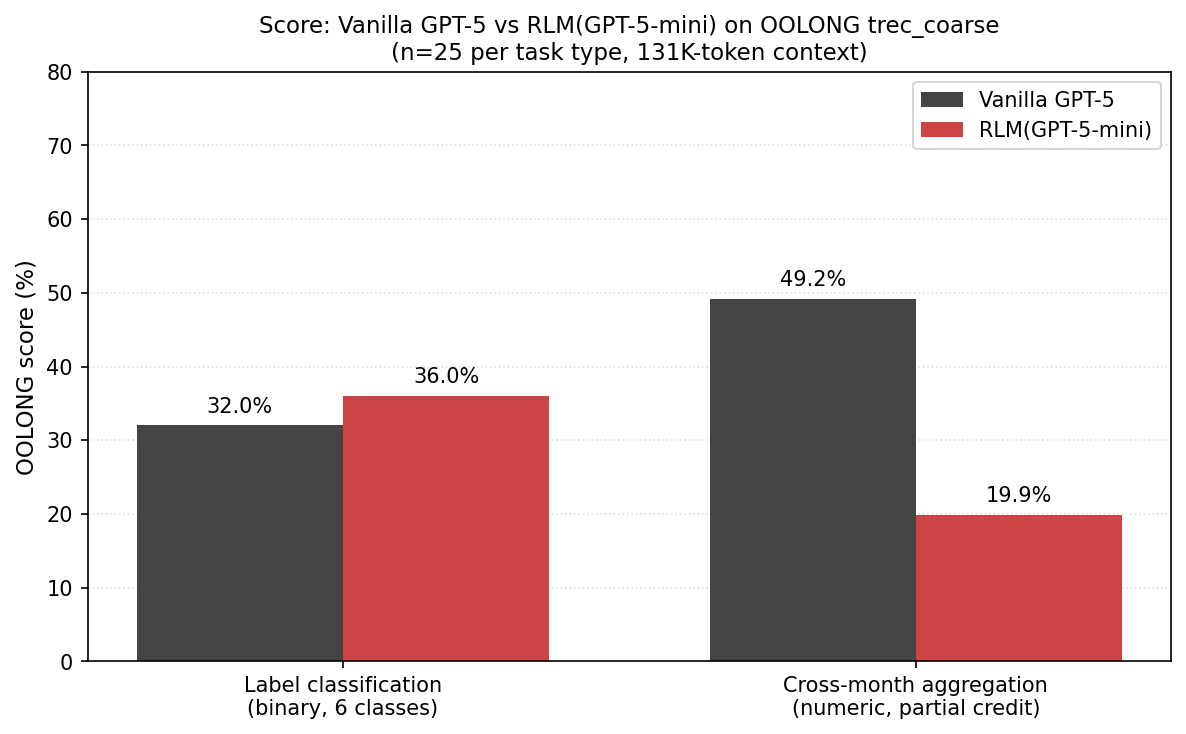
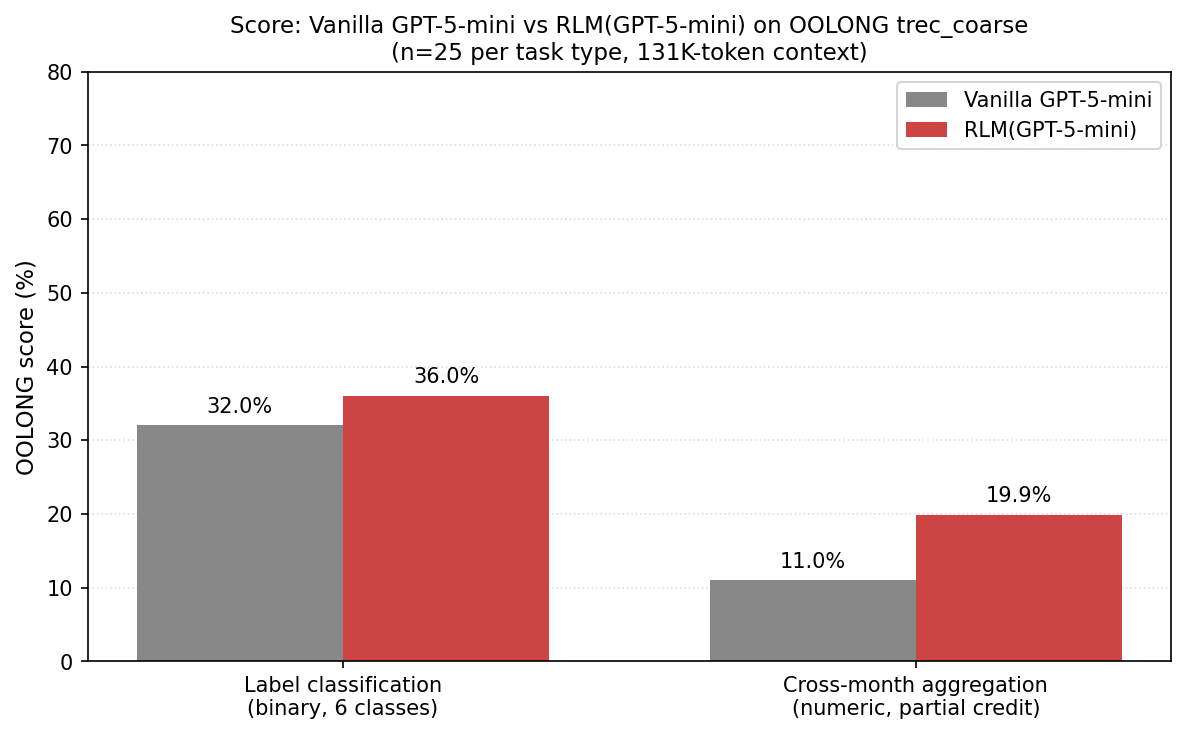
The blog post’s headline claim is that RLM(GPT-5-mini) outperforms vanilla GPT-5 “by more than double the number of correct answers, and is cheaper per query on average”. Using the researchers’ published RLM library, I generated two OOLONG task types: task_group=counting, task=LEAST_FREQ (6-way label classification) and task_group=timeline, task=MOST_FREQ (cross-month aggregation count), where each data set had 25 tasks apiece. The task types were selected to be mildly favorable and mildly unfavorable to RLM, to see differences. In my view, the OOLONG 50-task pool is far too small and elides over potentially interesting differences in task types. The same context window as the paper (131K)1 was used, as well as the last revision of the code (commit 97bbe97) at the time of the latest version of the paper (v3). GPT-5/mini used default parameters, including medium reasoning, also matching the paper.
I want to note that while I used their official RLM repo (the latest version of which has different prompts), there’s no script I can run to be sure my invocation is identical to theirs, and no way to reproduce their experiments using some of their other methods, e.g., OpenCode or Claude Code, at least not without a great deal of guesswork.
Testing this produced the opposite of the blog post’s claims! The results are below:
| Task type (n=25 each) | Vanilla GPT-5 | RLM(GPT-5-mini) |
|---|---|---|
| 6-way label classification (binary scored) | 32% (8/25) | 36% (9/25) |
| Cross-month aggregation count (partial credit) | 49.2% | 19.9% |
| Combined mean score | 40.6% | 28.0% |
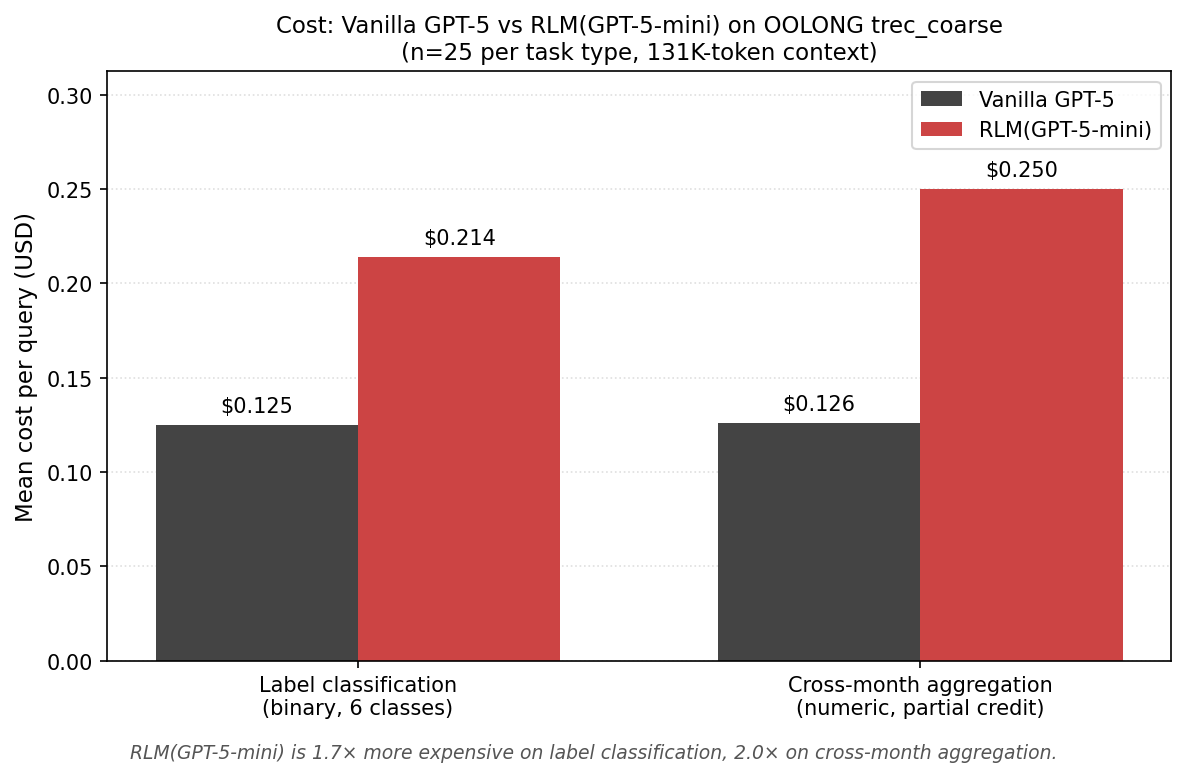
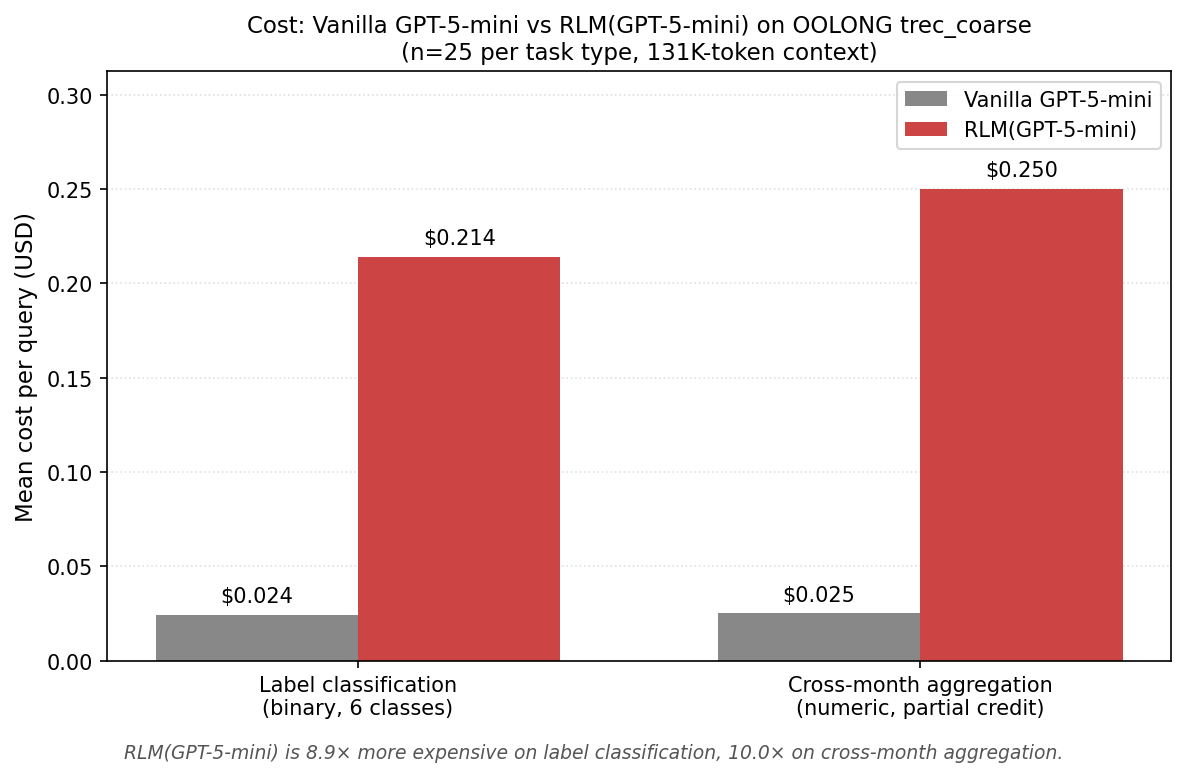
| Mean cost per query | $0.125 | $0.232 |
| Total cost over 50 runs | $6.27 | $11.59 |
| Mean wall time per query | 14s | 334s |
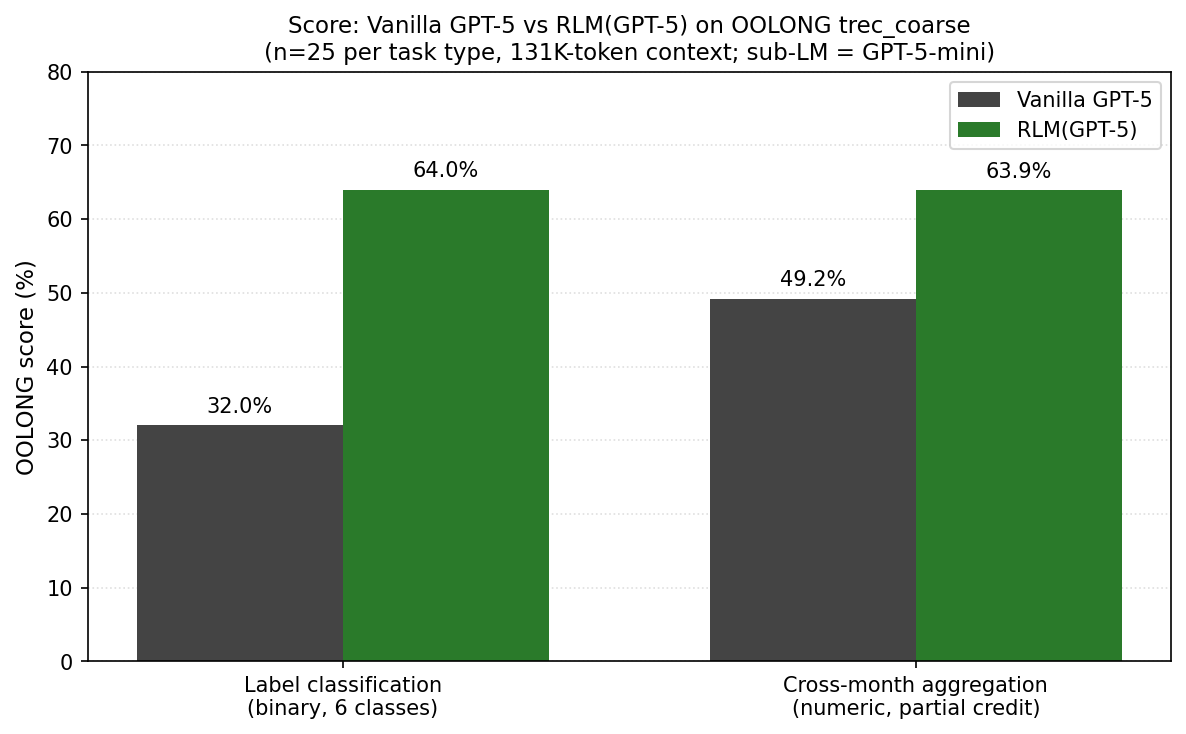
The paper, unlike the blog post, discussed what they call RLM(GPT-5), which means an RLM used GPT-5 as its root model and GPT-5-mini as its recursive calls2. This paper’s results look more plausible, but are grossly underpowered. However, I quickly found there is no codebase available to actually let me directly reproduce the results! Attempting to reproduce them in the same fashion as the paper claims did show some lift:
| Task type (n=25 each) | Vanilla GPT-5 | RLM(GPT-5) |
|---|---|---|
| 6-way label classification (binary scored) | 32% (8/25) | 64% (16/25) |
| Cross-month aggregation count (partial credit) | 49.2% | 63.9% |
| Combined mean score | 40.6% | 64.0% |
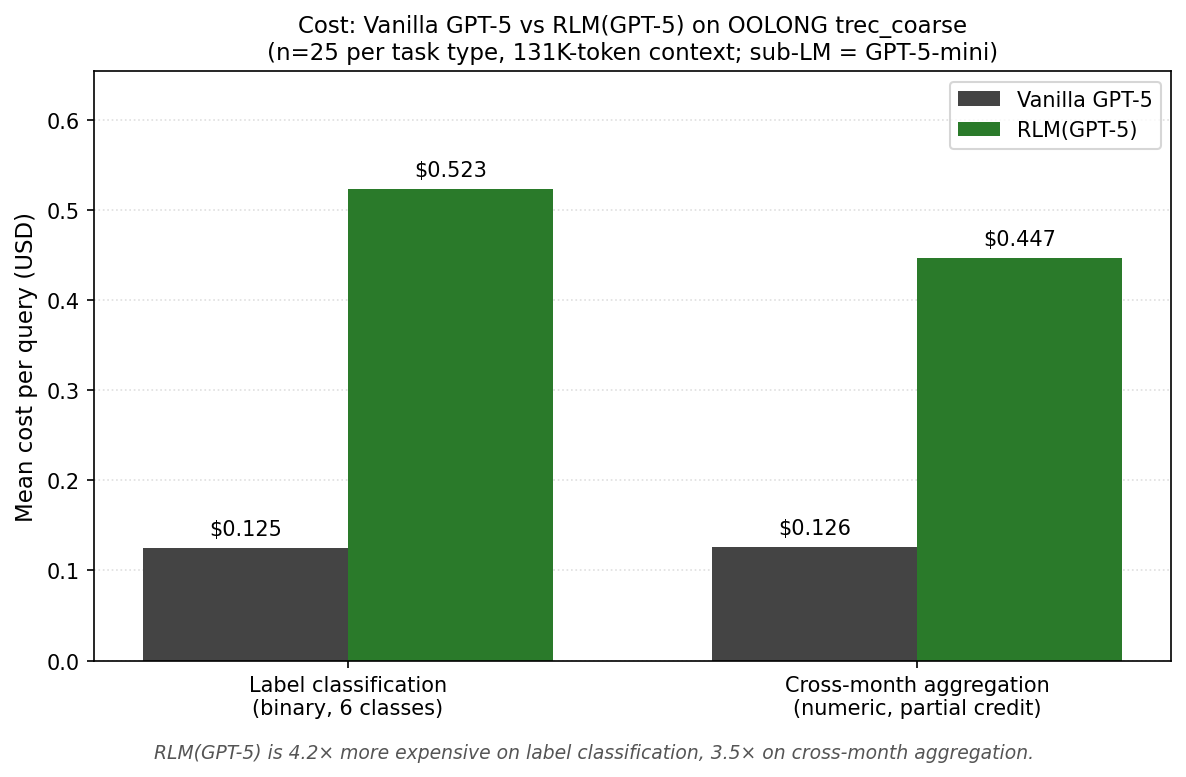
| Mean cost per query | $0.125 | $0.485 |
| Total cost over 50 runs | $6.27 | $24.26 |
| Mean wall time per query | 14s | 439s |
They also test against a bespoke OOLONG-Pairs benchmark but, again, don’t publish an implementation.
I’m able to see some mild but directionally-correct results, although I’d need far more runs to try and get statistical significance3. I suspect some actual statistical analysis would clarify the state of the paper. I’ve copied their results table below:
| Model | CodeQA | BrowseComp+ (1K) | OOLONG | OOLONG-Pairs |
|---|---|---|---|---|
| Task Length N (tokens) | 23K–4.2M | 6M–11M | 131K | 32K |
| GPT-5 (with RLM sub-calls to GPT-5-mini) | ||||
| Base Model | 24.0* ($0.13 ± $0.07) | 0.0* (N/A) | 44.0 ($0.14 ± $0.02) | 0.1 ($0.16 ± $0.10) |
| CodeAct (+ BM25) | 22.0* ($0.06 ± $0.08) | 51.0 ($0.71 ± $1.20) | 38.0 ($0.61 ± $1.06) | 24.7 ($0.75 ± $0.43) |
| CodeAct (+ sub-calls) | 24.0* ($0.06 ± $0.08) | 0.0* (N/A) | 40.0 ($0.85 ± $1.27) | 28.4 ($1.11 ± $0.62) |
| Compaction agent | 58.0 ($1.31 ± $1.46) | 70.5 ($0.57 ± $0.10) | 46.0 ($0.13 ± $0.01) | 0.1 ($0.13 ± $0.09) |
| OpenCode | 18.0* (N/A) | 0.0* (N/A) | 32.0 (N/A) | 3.1 (N/A) |
| OpenCode (+ context offloading) | 64.0 (N/A) | 94.0 (N/A) | 52.0 (N/A) | 4.8 (N/A) |
| RLM (recursion depth=0) | 58.0 ($0.18 ± $0.56) | 88.0 ($0.44 ± $0.90) | 36.0 ($0.37 ± $0.42) | 43.9 ($0.69 ± $1.16) |
| RLM (recursion depth=1) | 62.0 ($0.11 ± $0.10) | 91.3 ($0.99 ± $1.22) | 56.0 ($0.43 ± $0.85) | 58.0 ($0.33 ± $0.20) |
| RLM (recursion depth=2) | 66.0 ($0.15 ± $0.30) | 92.0 ($0.55 ± $0.69) | 56.5 ($1.10 ± $3.25) | 65.5 ($0.33 ± $0.44) |
| RLM (recursion depth=3) | 58.0 ($0.15 ± $0.27) | 92.0 ($0.51 ± $0.54) | 58.0 ($0.51 ± $0.54) | 76.0 ($0.39 ± $0.32) |
| Claude Opus 4.1 | ||||
| Claude Code | 12.0* ($2.03 ± $0.57) | 0.0* (N/A) | 40.2 ($3.43 ± $1.60) | 0.1 ($6.75 ± $3.57) |
| Claude Code (+ context offloading) | 62.0 ($1.25 ± $0.54) | 84.0 ($2.03 ± $1.49) | 48.0 ($0.98 ± $0.55) | 6.5 ($2.99 ± $1.16) |
A few things stand out:
1) OpenCode w/ GPT seems comparable to RLM on everything other than their bespoke OOLONG-Pairs benchmark. This makes a lot of intuitive sense. It implies that (i) giving the agent code execution is responsible for almost all of the gains and (ii) the “recursive” innovation would be highlighted by showing gains in comparison to OpenCode, not vanilla GPT.
2) Recursion depth >1 burns a lot of tokens for roughly equivalent or marginal performance, outside of their bespoke benchmark. This suggests to me that the costly agent model may in fact be optimal! The Qwen finetune doesn’t look much better, so I’m skeptical that more RL will fix this any time soon.
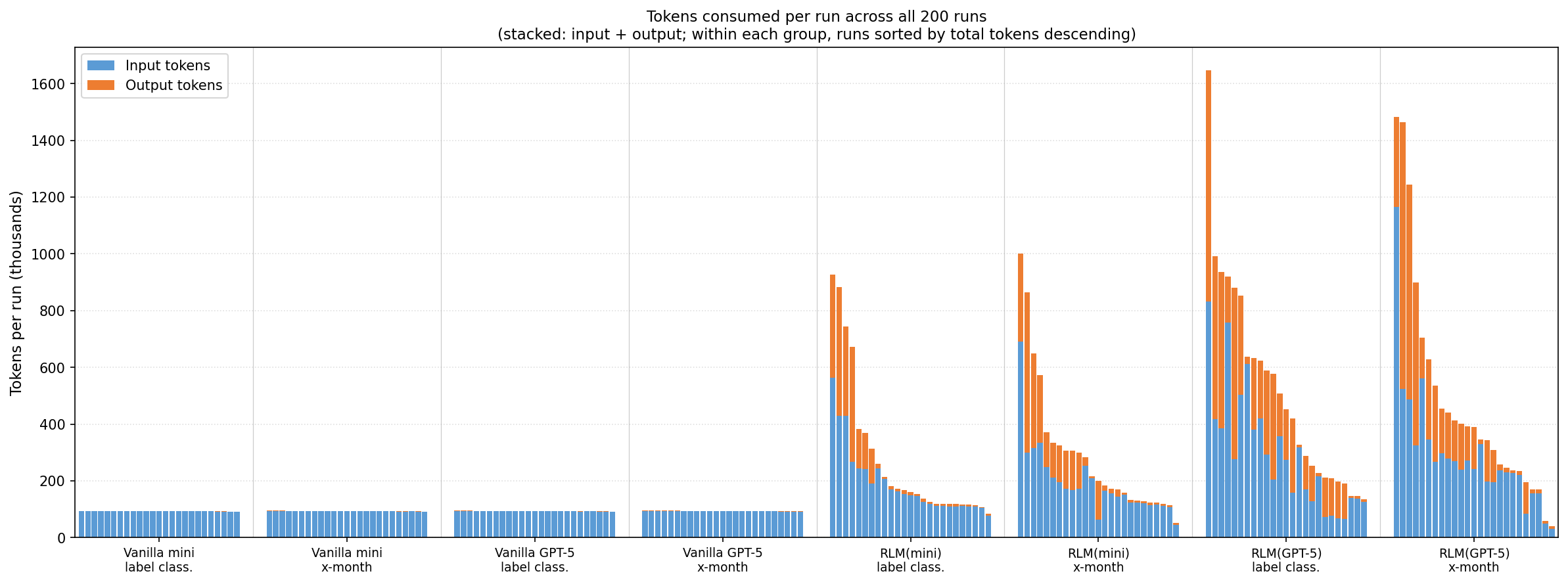
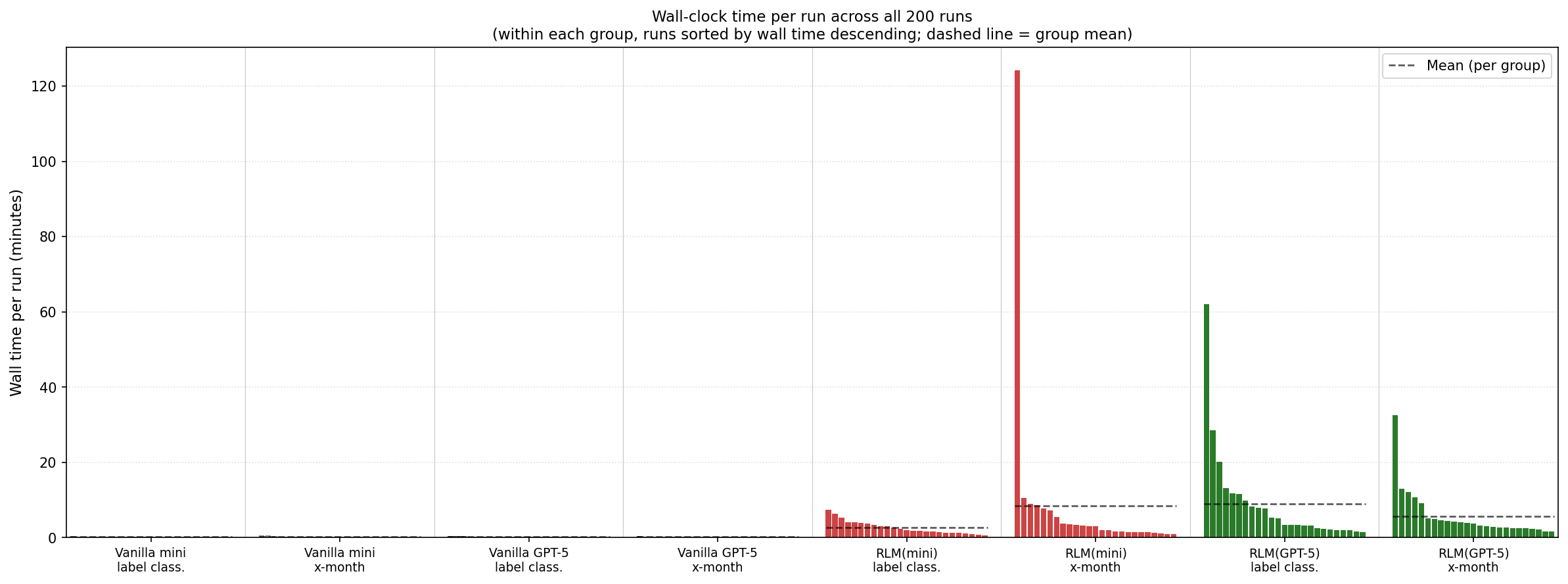
3) The papers undersells how bad the long tail is on wall clock time/tokens/cost, especially under high recursion depth. I had multiple tasks take over an hour, consuming orders of magnitude more tokens, just to produce the wrong answer.
If deeper recursion actually provides value, it should be possible to train an open-source model with better performance than OpenCode on others’ benchmarks. It should also be easy for other people to reproduce the results. (This is the point of open science!) My sense is that this won’t happen, because deeper recursion doesn’t actually work particularly well — which is itself interesting! “We tried this, and it didn’t work?!” is a perfectly fine result. Presenting the method otherwise, and making the results difficult to reproduce, wastes people’s time. The blog post should separately be edited or deleted, as it is false and diverges significantly from the paper.
The main author seems to dismiss or resent the Claude Code comparison, but I find his arguments (here and here and here) unconvincing. The paper also seems to avoid the subject. His responses are conceptual, but the field nowadays is fairly empirical (sorry to everyone upset about this!). The concepts are only valuable if they’re true, and if they fail to produce results, I am skeptical.
If I’m wrong, I’d love a more focused, reproducible paper or post. I think the research direction is interesting, and it’s plausible that deeper recursion will work eventually (and yield superior results to any other random coding harness), so I’m not saying to abandon RLMs.
I’d just like to see less hype and better science, so we can be confident the results are real.
Appendix
Tokens consumed:
Wall clock time:
Vanilla GPT-5-mini vs RLM(GPT-5-mini):
-
1: Claude was unhappy with this and wanted me to be more precise. Quoting Claude: “We actually generated 316K characters targeting context_len=131072 per OOLONG’s convention, which the gpt-5 tokenizer counted as ~93K tokens (OOLONG’s PER_EXAMPLE_TOKENS=39 estimate was based on gpt-4’s tokenizer and slightly over-counts for gpt-5).” ↩
-
2: It is not lost on me that this is no longer recursion. ↩
-
3: Which the paper also failed to do, or note as a limitation, but this seems to be quite common in the field. I’ll comment on this in a separate post. ↩